
- 闲来无事,想爬一下知乎热榜,说到爬虫肯定会想到python,那就试试看吧
- 本文记录下爬知乎热榜的过程,说实话也算不上是爬虫,毕竟分析过程中发现其实知乎本身就给了接口了,不过也能作为分析爬虫的一个参考吧
- 因为自己的“瞎搞”,现在是用python爬取数据并存入SQLite,毕竟在数据库里想怎么查都方便,后来为了做成一个接口随时可以爬取,还用php去调python来执行(好了别吐槽了=。=),其实代码也很简单,大佬可以绕道了2333
分析
首先打开知乎并按下F12,轻松找到自己要的东西,无非是要个当前榜单的标题,链接,热度,描述啥的,很好找,python用Xpath等来获取这些信息也很容易
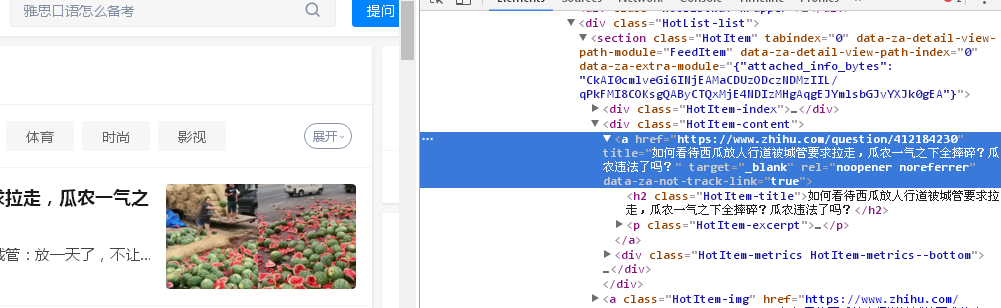
转念一想,这种内容肯定是动态生成的,照理说应该会访问一个接口来获取这些数据,再填充到页面上的,于是去Network看看,筛选XHR,果不其然,知乎请求了这个接口:https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=50&desktop=true,然后也拿到了我要的东西,那这就简单了,我直接从接口请求就好了~
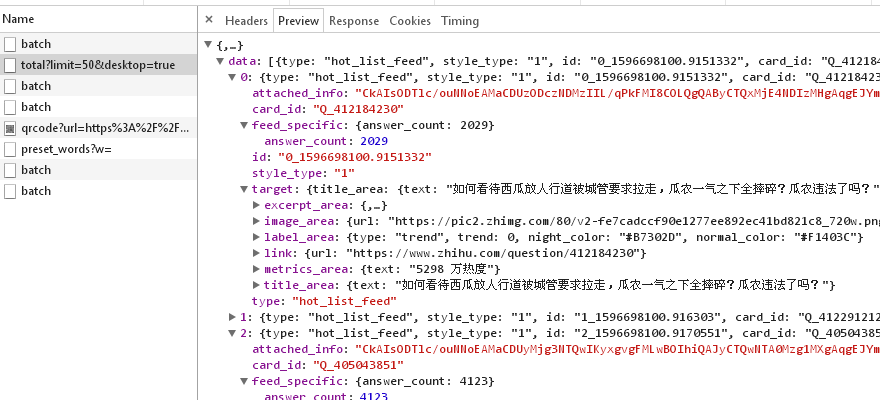
浏览器直接访问上面那个地址,可以看到获取到了目前热度前50的问题,返回内容如下:
{
"data": [{
"type": "hot_list_feed",
"style_type": "1",
"id": "0_1596698409.0986354",
"card_id": "Q_412184230",
"target": {
"id": 412184230,
"title": "如何看待西瓜放人行道被城管要求拉走,瓜农一气之下全摔碎?瓜农违法了吗?",
"url": "https://api.zhihu.com/questions/412184230",
"type": "question",
"created": 1596604290,
"answer_count": 2040,
"follower_count": 4167,
"author": {
"type": "people",
"user_type": "people",
"id": "0",
"url_token": "",
"url": "",
"name": "用户",
"headline": "",
"avatar_url": "https://pica.zhimg.com/aadd7b895_s.jpg"
},
"bound_topic_ids": [215, 5582, 13699, 17775, 30728],
"comment_count": 270,
"is_following": false,
"excerpt": "西瓜放人行道要求拉走被瓜农全摔碎,城管:放一天了,不让拉走 8月4日,吉林白城,目击者称瓜农把雨后摘下来的西瓜,堆放在人行道边上等大车装走。城管员看到后要求拉走,一气之下,瓜农把一大堆西瓜全部摔碎。 城管回应称,前一天已经放在那里,劝阻不听,不让我们拉走。"
},
"attached_info": "CkAIi/j3/MTKpuwQEAMaCDUzODczNDMzIIL/qPkFMI4COMcgQAByCTQxMjE4NDIzMHgAqgEJYmlsbGJvYXJk0gEA",
"detail_text": "5291 万热度",
"trend": 0,
"debut": false,
"children": [{
"type": "answer",
"thumbnail": "https://pic2.zhimg.com/80/v2-fe7cadccf90e1277ee892ec41bd821c8_720w.png"
}]
},
...以下省略...
}
好的,咱们开始写代码吧~
编写代码
首先要确保python安装了requests模块,若没有安装,执行pip install requests即可
爬取并保存到数据库
先贴出代码,后面再进行解释
# -*- coding:utf-8 -*-
import requests
import json
### ====================处理编码问题====================
#import sys
#import io
#sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
### ====================处理编码问题====================
import sqlite3
import time
import os
# 获取接口数据
def getData():
# 伪装成浏览器
headers = {'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
# 发送请求并获取结果
req = requests.get('https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=50&desktop=true', headers=headers)
# 获取数据并转为json
data = req.json()
data = data["data"]
print("<==get " + str(len(data)) + " data==>")
return data
# 数据库路径,供后面使用
dbPath = os.path.abspath(os.path.dirname(__file__)) + '/db/zhihu.db'
# 检查数据库.db文件
def checkAndCreateDB():
# 第一次运行时数据库文件不存在则创建
try:
#f =open('db/zhihu.db','r')
f =open(dbPath,'r')
f.close()
except FileNotFoundError:
print("<==database is not found, create...==>")
#conn = sqlite3.connect('db/zhihu.db')
conn = sqlite3.connect(dbPath)
# id question_id title popularity_index popularity time
c = conn.cursor()
c.execute('''CREATE TABLE ZHIHU
(ID INTEGER PRIMARY KEY NOT NULL,
QUESTION_ID TEXT NOT NULL,
TITLE TEXT NOT NULL,
POPULARITY_INDEX INT NOT NULL,
POPULARITY TEXT NOT NULL,
TIME _STAMP INT NOT NULL,
FORMATTED_TIME TEXT NOT NULL);''')
print("<==Table created successfully==>")
conn.commit()
conn.close()
# 保存数据到数据库
def saveData(data):
# 连接数据库
conn = sqlite3.connect(dbPath)
c = conn.cursor()
# 提取需要的数据并存入数据库
popularityIndex = 1
for obj in data:
questionId = str(obj["target"]["id"])
title = str(obj["target"]["title"])
popularity = str(obj["detail_text"])
#print("url--->" + "https://www.zhihu.com/question/" + questionId)
sql = "INSERT INTO ZHIHU (QUESTION_ID,TITLE,POPULARITY_INDEX,POPULARITY,TIME,FORMATTED_TIME) \
VALUES ('" + questionId + "', '" + title + "', " + str(popularityIndex) + ", '" + popularity + "', " + str(int(time.time())) + ", '" + time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())) + "' )"
c.execute(sql)
popularityIndex = popularityIndex + 1
# 提交并关闭数据库
conn.commit()
conn.close()
# 定时执行
def schedule(sec):
now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print("<==begin collect data: " + now + "==>")
data = getData()
saveData(data)
print("<==finished==>")
nextTime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time() + sec))
print("<==nextTime: " + nextTime + "==>\n")
timer = Timer(sec, schedule, (sec,))
timer.start()
def main():
#checkAndCreateDB()
#saveData(getData())
# 30min爬取一次
schedule(30*60)
if __name__ == '__main__':
main()
getData()请求知乎热榜的接口,因为接口返回的内容已经是JSON了,没必要作为字符串处理,于是req.json()将其转换为JSON对象,方便获取需要的数据
checkAndCreateDB()用于第一次运行脚本时检查是否存在数据库文件,不存在的话就创建,我这里只保存了热榜的问题ID(虽然接口返回了问题的url,但是url是https://api.zhihu.com/questions/问题ID进行拼接的,所以只保存问题ID省点空间),标题,当前热度排行,热度,时间,有需要其他信息的可以自行添加
saveData(data)用于保存数据到数据库,同样,有需要添加其他信息的可以自行添加
schedule(sec)加一个定时器,我计划是30min爬取一次,可以一直运行着
前面import注释掉了处理编码问题那三行代码,如果用windows的cmd直接执行,可能会出现UnicodeEncodeError的错误,这个时候把那三行代码的注释去掉就可以了,解决办法参考了这里,linux的话一般没问题的
查询数据
就简单写了下查询所有数据,有需要的话可以做成在命令那里注入SQL呀,或者做个查询界面啥的,这里就不展开了
import sqlite3
conn = sqlite3.connect('db/zhihu.db')
print("Opened database successfully")
c = conn.cursor()
cursor = c.execute("SELECT * from ZHIHU")
# id question_id title popularity_index popularity time
col_name_list = [tuple[0] for tuple in cursor.description] # 获取列名
print(col_name_list)
for row in cursor:
for i in range(len(row)):
print(col_name_list[i] + "-->" + str(row[i]))
cursor.close()
conn.close()
php调用
- 等我写完上面那坨后,突然意识到,我希望能够做成一个接口,每请求一次就执行一次,就不做成定时任务了
- 然后发现蠢哭了,因为知乎本身就提供了接口,其实我全程用php就ok了,反正我的云服务器有php环境=。=
- 行吧懒得重写了,那就在php中调用python吧
- 因为我的服务器的服务都是用docker进行部署了,php镜像并没有python3环境,所以为了它还特意做了一个php+python3的镜像,参考我另一篇文章:docker在php镜像基础上构建python3环境
只要系统同时有php+python3的环境,就可以用下面的代码调用
<?php
//$output = system('python3 zhihu.py');
$output = exec('python3 zhihu.py');
echo $output.'<br/>';
echo 'success'
?>
唔没错,前面那篇docker在php镜像基础上构建python3环境就只是为了实现这个...有点小题大做了点,不过积累些经验也好233333